shellphish/how2heap是一个学习各种学习各种堆利用技术的wargame。
本篇文章作为学习笔记加上一些个人理解。只做了Glibc>=2.31版本的,前面部分是用的2.31版本的Glibc,后面部分是较新的2.34版本的Glibc(从tcache_poisoning.c开始)。
fastbin_dup_into_stack.c
版本: Glibc-2.31
Tricking malloc into returning a nearly-arbitrary pointer by abusing the fastbin freelist.
源程序是先把tcache bin填满,这样free的时候chunk会插入到fastbin中,而不是tcachebin。
第一次free,chunk a插入到fastbin链表头.
pwndbg> bins
+bins
tcachebins
0x20 [ 7]: 0x555555559360 —▸ 0x555555559340 —▸ 0x555555559320 —▸ 0x555555559300 —▸ 0x5555555592e0 —▸ 0x5555555592c0 —▸ 0x5555555592a0 ◂— 0x0
fastbins
0x20: 0x555555559370 ◂— 0x0
fastbins只会对头部的chunk有double free检测。检测方法是比较fastbin顶部的chunk与传进来将要释放的的chunk的地址进行比较,如果相同,说明double free。检测部分的代码逻辑在malloc.c:4265
double free之后,fastbin成这样,成一个环。
pwndbg> fastbins
+fastbins
fastbins
0x20: 0x555555559370 —▸ 0x555555559390 ◂— 0x555555559370
0x30: 0x0
0x40: 0x0
0x50: 0x0
0x60: 0x0
0x70: 0x0
0x80: 0x0
两次分配0x20大小的chunk之后,fastbin顶部chunk可写的同时在链表上等待分配。
pwndbg> fastbins
+fastbins
fastbins
0x20: 0x555555559370 ◂— 0x0
0x30: 0x0
0x40: 0x0
0x50: 0x0
0x60: 0x0
0x70: 0x0
0x80: 0x0
这时我们可以将顶部chunk的fd字段写为一个任意地址,在分配一次之后的下一次fastbin返回的chunk的地址就是我们构造的地址。其中够造的伪chunk大小要和fastbin所在下标一致malloc.c:3594
fastbin_dup_consolidate.c
TL;DR
简单的说就是释放后指针还指向原来的chunk,可以用原来的指针释放chunk,看起来像double free。
技术分析
版本: Glibc-2.31
Tricking malloc into returning an already-allocated heap pointer by putting a pointer on both fastbin freelist and unsorted bin freelist.
为分配的为1024字节,需要1040字节chunk大小,超出了smallbin支持的最大大小,此时又有fastbin,触发malloc_consolidate函数malloc.c:3699,合并chunk放到unsorted bin。
23 void* p3 = malloc(0x400);
malloc_consolidate函数的操作就是将fastbin中内存上相邻的chunk合并并把它们放到unsorted bin中(malloc.c:4468)。但如果内存上下一个chunk是top chunk,那么该chunk将直接会和top chunk合并,就不放到unsorted bin中了。
所以,该程序中fastbin上顶部的chunk释放后,后面分配触发malloc_consolidate函数执行合并,会将fastbin中的chunk合并到top chunk中,然后从top chunk中切下所需要的大小分给用户。分配完成后chunk的地址是相同的(相当于chunk扩了一截,然后再给它分配出去)。
此时dobule free p1,相当于用p1指针释放p3指针得到的chunk。
31 printf("Triggering the double free vulnerability!\n\n");
32 free(p1);
再分配会分配到相同的地址。
这种情况感觉对库来说不好防。
unsafe_unlink.c
环境: Glibc 2.31
合并处的入口malloc.c:4327
unlink_chunkmalloc.c:1451
流程大概是在数据部分做了一个假的空chunk,然后让后面内存相邻的chunk在free时把前面的假chunk给合并了。在unlink的时候,全局变量中的值就被覆盖掉了。
unlink导致全局变量被覆盖的语句的位置是malloc.c:1462。
一图胜千言:
chunk1_hdr chunk1_ptr
| |
| |
| |
+--------|-----|------|------|------|-----------------|----v-|--------|-v---|---------+
| | | | | | | | | | |
| | | | | | | | | | |
| | | | | | | | | | |
| | |fake | fake | fake | | fake | | | |
| Chunk0 | |free | free | free | ...... | free | chunk1 | | ..... |
| size | |chunk | chunk| chunk| | chunk| size | | |
| | |size | fd | bk | | size | | | |
| | | | | | | | | | |
| | | | | | | | | | |
+--------|^-^--|------|--|---|--|---|-----------------|------|--------|-----|---------+
| | | |
| | | |
| +------------------------------+ before free!!!
fake free | | | |
chunk header-------------+ | | |
+------|--v--|---v-|-----|--|---|--------+
| | | | | | | |
| | | | | | |
| | | | |globle| |
| | | | |chunk0| |
| | | | |ptr | |
| | | | | | | |
+------|--^--|-----|-----|--|---|--------+
| |
| |
| |
| |
|-----------------+
after free!!!
地址增长的方向为从左至右。一个格子的大小为一个机器字长。 before/after free!!!分别表示unsafe_unlink.c:49语句前后。
This technique can be used when you have a pointer at a known location to a region you can call unlink on.The most common scenario is a vulnerable buffer that can be overflown and has a global pointer.
house_of_spirit.c
环境: Glibc 2.31
TL;DR:
说白了就是伪造一个之前根本没有malloc的chunk。free后放到fastbin中,下次分配从fastbin中取伪造的chunk分配给用户。
用户申请的大小转化为实际的chunk大小的checked_request2size函数malloc.c:1206:
一图胜千言
+------|------|------|-------------------------------------|------|------+
| | | | | | |
| | | | | | a |
| | | | | | sane |
| | | | | | chunk|
| |fake | fake | | | size |
| |chunk | chunk| ..... | | |
| |size | data | | | |
| | | start| | | |
| | | here | | | |
| | | | | | |
| | | | | | |
| | | | | | |
+--^---|------|-^----|-------------------------------------|-^----|------+
| | |
| | |
| +--------------------victim |
| |
| |
fake chunk next fake chunk
header(i.e.,fake_chunks) header
每个格子代表一个机器字。地址空间从左往右增大。
victim指向的地址就是下次malloc分配给用户的地址。
poison_null_byte.c
运行环境: Glibc 2.31
最后构造出来,差不多长这样:
|-----------------------------------------------------------------------------------------------------------------------+
| |
| |
+-----|-----|--|--|-----|-----|-----|-----------------|-----|------|-----|----|------------+ |
| | | v | | | | | | | | | | +----|-----|----|--|--|-------------+
| |prev |prev |fake |fake |fake | | | | | | | | | | | | | |
| |chunk|fd |free |free |free | | |victim| | | | | | | | | |
| |size | |size |fd= |bk= | | 500 |size | | | | | |500 |fd | bk | |
| |510 | |500 |prev |prev | | |500 | | | | | | | | | |
| | | | |chunk|chunk| | | | | | | | | | | | |
| | | | |fdnx |bknx | | | | ^ | | | | | | | | |
| | | | | | | | | | | | | | | | | ^ | | ^ | | |
+-----|-----|^---^|-----|--|--|--|--|-----------------|-----|------|-|---|----|------------+ +-|--|-----|-|--|-----|-------------+
| | | | | | |
| | | | victim | |
| | | | | |
| | +-----|------------------------------------------------------------------------------------| a
| prev=prev2 |
| =fake chunk header|
| |
|---------------------------------------------------------------+
| |
| |
| |
| |
| +-----|-----|--|--|------------------------------+
+--------------------------->| | | | | |
| | | | |
| |chunk|fd | |
| |size | | |
| |520 | | |
| | | | |
| | | | |
| | | | |
+-----|-----|-----|------------------------------+
^
|
|
|
b
每个格子代表一个机器字。地址空间从左往右增大。
看起来就是构造一个fake free chunk,victim在释放时合并fake chunk,放到unsorted bin上。最后分配时从合并的chunk切下一段,fake chunk和prev chunk 有重叠,导致可以一次写两个”chunk”。
关键点:
- 分配堆的时候让”堆开始”的末尾的4字节地址为0,使得推断堆上chunk最后两位地址成为可能。
- 绕过unlink的双链检查。
下面的输出说明只需要改最后两字节,就能操纵chunk 的fd,bk指针(修改指针所存地址的最后两位)指向我们想要的chunk。
Current Heap Layout
... ...
padding
prev Chunk(addr=0x??0010, size=0x510)
victim Chunk(addr=0x??0520, size=0x500)
barrier Chunk(addr=0x??0a20, size=0x20)
a Chunk(addr=0x??0a40, size=0x500)
barrier Chunk(addr=0x??0f40, size=0x20)
b Chunk(addr=0x??0f60, size=0x520)
barrier Chunk(addr=0x??1480, size=0x20)
house_of_lore.c
运行环境: Glibc 2.31
其大概流程就是在栈上构造了一个free list。然后使samllbin中的顶部chunk的bk连上栈上的构造的free list。在malloc.c:3661行,smallbin会补充tachebin,下次分配时就从栈上构造的free list(tcachebin)上拿chunk了。
在house_of_lore.c:120行执行之前的图示:
+-----------------|-----+
| | |
| ^ | null|
+--|--------------|-----+
|
...........
------------------+ -|-----------------------------------------------+
+-----------------|--|--+ | +----|----|----|--|--+
| | | | | | | | | | |
| ^ | bk | | +-----------------> | |fd | bk |
+-|---------------|-----+ | | | | | | |
-------------------+ | | +----|----|-^--|-----+
| | | |
+-----------------|--|--+ | | |
| | | | | | |
| | bk | | | victim
+-^---------------|-----+ | | small bin top chunk
| | |
|------------------+ | |
| | |
+-----------------|--|--+ | |
| | | | | |----------------------------------------------------------------+
| | bk | | | | |
+^-^--------------|-----+ | | | |
| | | | | |
| | +-v-v|-----|--|-|----+ +----|-----|-|--|----+
| | | | |fd| |bk | | | | | |
| | | | | | -----------------------------------> | |fd | bk |
| fake_freelist | | | | | | | | | | |
| +-^--|-----|----|----+ +-^--|-----|----|--|-+
| | | |
| | | |
| stack_buffer_1 stack_buffer_2 |
|------------------------------------------------------------------------------------------------------------------+
每个比较小的格子代表一个机器字。大格子内地址空间从左往右增大。
调试发现他返回的是fake_freelist[4]的内存位置,tcache bin补充的顺序是stack_buffer_1,stack_buffer_2,fake_freelist[0]…fake_freelist[4],正好7个,头插加入tcachbin。samllbin每次从samllbin头部的bk取。
构造过程中注意双链检查。
mmap_overlapping_chunks.c
环境: Glibc 2.31 (Glibc 2.32版本以上的tcach bin投毒在下一节。)
原始文件mmap_overlapping_chunks.c:51行会进行调用malloc分配一个chunk作为printf缓冲区。
51 printf("This is performing an overlapping chunk attack but on extremely large chunks (mmap chunks).\n");
如果不想让printf使用缓冲机制,即不想让printf分配上述chunk。 在printf前调用setbuf(stdout, NULL);。
mmap按页分配。在top_ptr,mmap_chunk_2,mmap_chunk_3分配完了(在0x7ffff7b12000 0x7ffff7e15000 0x303000位置),内存中布局长这样:
pwndbg> info proc mappings
+info proc mappings
process 40598
Mapped address spaces:
Start Addr End Addr Size Offset objfile
0x555555554000 0x555555555000 0x1000 0x0 /home/z1933/workplace/vbshare/ctf/how2heap/glibc_2.31/mmap_overlapping_chunks
0x555555555000 0x555555556000 0x1000 0x1000 /home/z1933/workplace/vbshare/ctf/how2heap/glibc_2.31/mmap_overlapping_chunks
0x555555556000 0x555555557000 0x1000 0x2000 /home/z1933/workplace/vbshare/ctf/how2heap/glibc_2.31/mmap_overlapping_chunks
0x555555557000 0x555555558000 0x1000 0x2000 /home/z1933/workplace/vbshare/ctf/how2heap/glibc_2.31/mmap_overlapping_chunks
0x555555558000 0x555555559000 0x1000 0x3000 /home/z1933/workplace/vbshare/ctf/how2heap/glibc_2.31/mmap_overlapping_chunks
0x555555559000 0x55555557a000 0x21000 0x0 [heap]
0x7ffff7b12000 0x7ffff7e15000 0x303000 0x0
0x7ffff7e15000 0x7ffff7e3a000 0x25000 0x0 /home/z1933/Downloads/glibc-install/lib/libc-2.31.so
0x7ffff7e3a000 0x7ffff7f74000 0x13a000 0x25000 /home/z1933/Downloads/glibc-install/lib/libc-2.31.so
0x7ffff7f74000 0x7ffff7fbc000 0x48000 0x15f000 /home/z1933/Downloads/glibc-install/lib/libc-2.31.so
0x7ffff7fbc000 0x7ffff7fbd000 0x1000 0x1a7000 /home/z1933/Downloads/glibc-install/lib/libc-2.31.so
0x7ffff7fbd000 0x7ffff7fc0000 0x3000 0x1a7000 /home/z1933/Downloads/glibc-install/lib/libc-2.31.so
0x7ffff7fc0000 0x7ffff7fc3000 0x3000 0x1aa000 /home/z1933/Downloads/glibc-install/lib/libc-2.31.so
0x7ffff7fc3000 0x7ffff7fc9000 0x6000 0x0
0x7ffff7fc9000 0x7ffff7fcd000 0x4000 0x0 [vvar]
0x7ffff7fcd000 0x7ffff7fcf000 0x2000 0x0 [vdso]
0x7ffff7fcf000 0x7ffff7fd0000 0x1000 0x0 /usr/lib/x86_64-linux-gnu/ld-2.31.so
0x7ffff7fd0000 0x7ffff7ff3000 0x23000 0x1000 /usr/lib/x86_64-linux-gnu/ld-2.31.so
0x7ffff7ff3000 0x7ffff7ffb000 0x8000 0x24000 /usr/lib/x86_64-linux-gnu/ld-2.31.so
0x7ffff7ffc000 0x7ffff7ffd000 0x1000 0x2c000 /usr/lib/x86_64-linux-gnu/ld-2.31.so
0x7ffff7ffd000 0x7ffff7ffe000 0x1000 0x2d000 /usr/lib/x86_64-linux-gnu/ld-2.31.so
0x7ffff7ffe000 0x7ffff7fff000 0x1000 0x0
0x7ffffffdd000 0x7ffffffff000 0x22000 0x0 [stack]
0xffffffffff600000 0xffffffffff601000 0x1000 0x0 [vsyscall]
简约版,从libc-2.31.so的下面朝着堆地址的方向分配。调试出来内存布局长这样:
Current System Memory Layout
================================================
running program
heap
....
third mmap chunk
second mmap chunk
first mmap chunk
LibC
ld
===============================================
简单的说,就是修改third mmap chunk的大小,使得在释放时把second mmap chunk也给munmap了。下次分配时分配一个比之前加起来都大的空间,这样新分配的空间和second mmap chunk空间有重叠。
mp_.mmap_threshold在malloc.c:3113行更新。
可以用于overflow,或者不恰当的index。
large_bin_attack.c
环境: Glibc 2.31
利用的代码段为malloc.c:3840。如果足够小,会直接尾插到对应的largbin中,这里没有双链检查(检查比较弱)。largebin中的chunk从大到小排序。
在nextsize双链连接的时候,让target的”fd_nextsize”指向p2所在的chunk,写target所存的内容让target指向p2所在的chunk。
涉及到的代码片段:
3840 if ((unsigned long) (size)
3841 < (unsigned long) chunksize_nomask (bck->bk)) // 如果这个块足够小,那么只需将其以头插法 插入到链表尾即可
3842 {
3843 fwd = bck;
3844 bck = bck->bk;
3845
3846 victim->fd_nextsize = fwd->fd; // nextsize循环双向链表, fd_nextsize,bk_nextsize域分别构成> 一个方向相反的循环链表。
3847 victim->bk_nextsize = fwd->fd->bk_nextsize;
3848 fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim;
3849 }
3848行执行前的chunk示意图为:
+-----|------|------|-----|--------+
| | | | |target |
| | | fd |bk |(fdn) |
| | | | | |
+^--^-|------|------|-----|--------+
| |
| |
| |---------------------------------------------------------------------------------------------+
| +-----|-------|------|------|-------|---|--+
| | | | | | | | |
| | | 430 | fd | bk | fdn |bkn |
| +-------------------------->| | | | | | |
| | +--^--|-------|--^---|------|-------|------+
| | | |
| | | |
|----------------------------|--------+ | |
| | fwd->fd p1
| |
| |
| |
| |
+-----|------|------|-----|-|-----|--|---+
| |420 | fd |bk | | | | |
| | | | | fdn | bkn |
+-^---|------|^-----|-----|-------|------+
| |
| |
| |
victim p2
fwd是对应的largbin链表头。数字是16进制。fdn是fd_nextsize的简写。bkn依次类推。target前的fd,bk是没有的,写上是为了方便表达。
malloc.c:3848行fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim;执行之后,target就指向p2的chunk头了。
house_of_einherjar.c
环境: Glibc 2.31
大概先是用一个malloc后的空间构造了一个fake free chunk,然后在后面申请一个块。后面申请的块在free时向前合并就把我们的fake free chunk合并了。下次申请时返回的是我们构造的fake chunk。
在c释放前的堆差不多长这样:
+------|----|-----|-----|-----|----------------------|----|----|----|----------------------|-----|----|----|-------------------+
| | | | | | | | | | |fake | | | |
| 64 | 0 | 96 | fd | bk | | 48 |fd | | |size | | | |
| | | | | | | | | | |=96 | 256| | |
| | | | | | | | | | | | | | |
+------|--^-|-----|-^---|-----|----------------------|----|-^--|----|----------------------|-----|----|-^--|-------------------+
| | | |
| | | |
| | | |
a | b c
fake
其中的数字是10进制。
tcache 投毒(tcache poisoning)
后面就是在用返回的fake chunk写一个放到tcache bin上的chunk的fd(即free(b)后),使其指向我们想要的位置。第二次malloc返回就是我们想要的地址。新版本的投毒参见下一节。
下面这段pad的作用:
116 // tcache poisoning
117 printf("After the patch https://sourceware.org/git/?p=glibc.git;a=commit;h=77dc0d864
118 "We have to create and free one more chunk for padding before fd pointer hija
119 uint8_t *pad = malloc(0x28);
120 free(pad);
加一个pad的作用是使得头插的这个条件tcache->counts[tc_idx] > 0成立。即下面这个条件判断成立:
if (tc_idx < mp_.tcache_bins
&& tcache
&& tcache->counts[tc_idx] > 0)
{
return tcache_get (tc_idx); // tcache中对应的bin恰好有,直接返回tcache的bin
}
在源文件的位置为:malloc.c:3047
tcache_poisoning.c
环境: Glibc 2.34
Glibc编译可以参考如何用gdb调试glibc源码编译。
写了个bash脚本,将目录下elf的加载器&动态链接器批量改成编译好的2.34版本:
#!/usr/bin/env bash
# 需要批量改变加载器的目录
path='.'
# 编译好的加载器目录
loaderpath='/home/z1933/workplace/warehouse/glibc-install/lib/ld-linux-x86-64.so.2'
# 修改
for entry in "$path"/*
do
if [[ -x "$entry" && "$entry" != "$0" ]]
then
patchelf --set-interpreter $loaderpath $entry
echo "$entry finish"
fi
done
其中loaderpath是你编译好的动态链接器的路径。
Safe-Linking makes use of randomness from the Address Space Layout Randomization (ASLR), now heavily deployed in most modern operating systems, to “sign” the list’s pointers.
在glibc2.32之后。添加对单链的保护。
让我们来看新版tcache bin 加单链的Glibc2.34:3070这段代码。
3059 /* Caller must ensure that we know tc_idx is valid and there's room
3060 for more chunks. */
3061 static __always_inline void
3062 tcache_put (mchunkptr chunk, size_t tc_idx)
3063 {
3064 tcache_entry *e = (tcache_entry *) chunk2mem (chunk);
3065
3066 /* Mark this chunk as "in the tcache" so the test in _int_free will
3067 |detect a double free. */
3068 e->key = tcache_key;
3069
3070 e->next = PROTECT_PTR (&e->next, tcache->entries[tc_idx]);
3071 tcache->entries[tc_idx] = e;
3072 ++(tcache->counts[tc_idx]);
3073 }
tcache->entries[tc_idx]里面存的还是没有”加密”的地址。
其中PROTECT_PTR宏:
350 #define PROTECT_PTR(pos, ptr) \
351 ((__typeof (ptr)) ((((size_t) pos) >> 12) ^ ((size_t) ptr)))
352 #define REVEAL_PTR(ptr) PROTECT_PTR (&ptr, ptr)
可以看出,其”加密”过程就是把chunk自己的地址右移12位,然后与要存的地址异或。”解密”的过程就是把自己的地址右移12位,与存的结果再异或12位得到原本的地址。
增加地址16bit对齐检查(32位是8bit)。
意味着如果想要劫持tcachbin返回我们想要的地址攻击者需要选一个16bit对齐的地址和知道要劫持的chunk在内存中的地址。
劫持时我们只需要将劫持chunk的fd赋值为chunk在堆中的地址右移12位 异或上 我们想要让其返回的地址。这样在REVEAL_PTR就会异或出我们想要的地址。也就是malloc.c:3083行,取出后让tcach bin指向我们的地址,下次再malloc就ok了。
对单链的保护的具体细节可以参考提出者写的这篇文章Safe-Linking – Eliminating a 20 year-old malloc() exploit primitive。
tcache_house_of_spirit.c
环境: Glibc 2.34
流程就是在栈上构造了一个fake chunk,fake chunk地址需要16位对齐,free会有对齐检查。free掉之后放入tcache bin,下次分配让malloc返回fake chunk。
house_of_botcake.c
环境: Glibc 2.34
就是构造让堆分配重叠。使得一个指针可以写下一个分配的chunk。平平无奇,不是返回任意地址。
tcache_stashing_unlink_attack.c
环境: Glibc 2.34
The mechanism of putting smallbin into tcache in glibc gives us a chance to launch the attack.
samllbin 尾部取,取出补充放到tcachbin.
构造了一个连续的chunk list。先把chunk3-8,chunk1 free放到tcache bin中,然后把0,2放到unsorted bin中。这样做的目的是让0,2 chunk不合并,并且可以把tcache bin塞满。
然后取出两个tcachebin中的chunk,用smallbin填充tcachebin机制将我们的假chunk填充到tcachbin中。倒车入库,samllbin是从尾部倒着填到tcachebin中的。
tcache_stashing_unlink_attack.c程序中这句话:
22 stack_var[3] = (unsigned long)(&stack_var[2]);
是为了让下面这句话(malloc.c:3814)有可写地址:
bck->fd = bin;
smallbin填充没有双链检查。检查比较弱。
fastbin_reverse_into_tcache.c
环境: Glibc 2.34
需要利用use after free,heap leak漏洞写victim的fd到我们想要的地址。然后让fastbin补充tcache bin的时候把我们想要的地址放到tcache bin中的第一个,作为假chunk,下一次malloc分配时返回的就是我们想要地址的chunk。
如果要返回的假chunk的fd是null的话,可以不用把tcachebin塞满。如果不是的话可以直接分配6个,使得tcachebin塞满自动结束。用fastbin填充tcachebin结束条件:malloc.c:3756
house_of_mind_fastbin.c
环境: Glibc 2.34
在堆上构造一个假的heap info,指向一个假的arena。假的heap info地址后面的chunk的non-main arena bit设置为1。free chunk的时候就会在假的arena中的fastbin中被记录,造成地址被写。
最后假的arena中的内容:
pwndbg> arena fake_arena
+arena fake_arena
{
mutex = 0,
flags = 0,
have_fastchunks = 1,
fastbinsY = {0x0, 0x0, 0x0, 0x0, 0x555558027110, 0x0, 0x0, 0x0, 0x0, 0x0},
top = 0x0,
last_remainder = 0x0,
bins = {0x0 <repeats 254 times>},
binmap = {0, 0, 0, 0},
next = 0x0,
next_free = 0x0,
attached_threads = 0,
system_mem = 16777215,
max_system_mem = 0
}
This is a WRITE-WHERE primitive. An attacker fully controls the location (memory address) being written to but NOT the value itself.
只能控制被写的地址,不能控制被写的内容(每次写都是一个堆内存上的地址)。或许可以用于覆盖一些最大值,造成溢出与可能的泄露。
更详细的细节可以参考poc提出者所写的文章:House of Mind - Fastbin Variant in 2021。
decrypt_safe_linking.c
环境: Glibc 2.34
解密单链的safe linking.
做的时候makefile中没有编译2.34版本的decrypt_safe_linking.c,但对应文件夹下有源代码文件。可能需要自己编译一下,在makefile中改一下版本再make一下即可。
加密过程是把自己的地址右移12位然后与下一个chunk的地址异或。
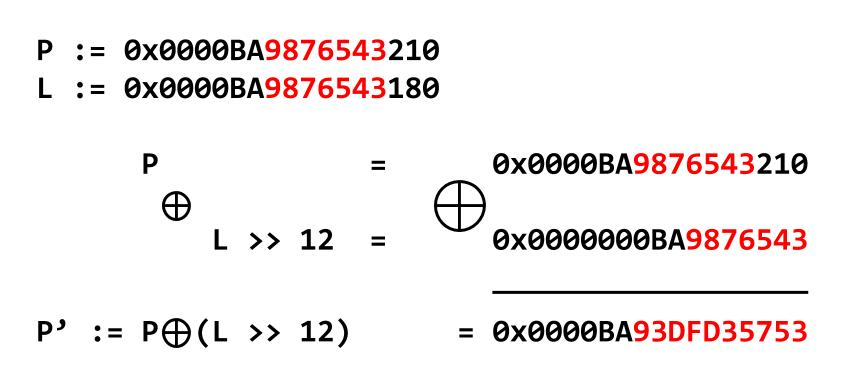
解密的依据是对于同一页上的chunks,从低位开始的第12位到高位是相同的,观察上上面的图可以发现这种情况下加密后的高12位地址没有变。
让我们直接来看程序输出的解密流程:
round 1:
key: 0000000000000000
plain: 0000000000000000
cipher: 0x0055e6e5bb4aaf
round 2:
key: 0x00000550000000
plain: 0x00550000000000
cipher: 0x0055e6e5bb4aaf
round 3:
key: 0x0000055e3b0000
plain: 0x0055e3b0000000
cipher: 0x0055e6e5bb4aaf
round 4:
key: 0x0000055e3bb800
plain: 0x0055e3bb800000
cipher: 0x0055e6e5bb4aaf
round 5:
key: 0x0000055e3bb80f
plain: 0x0055e3bb80f2a0
cipher: 0x0055e6e5bb4aaf
value: 0x55e3bb80f2a0
recovered value: 0x55e3bb80f2a0
第1轮到第2轮:
开始的plain的40-47bit,(下标从0开始,地址一共48bit)可以确定,plain右移12位后可以确定key的28-47bit.
第2轮到第3轮:
key的28-47bit可以反过来确定plain的28-47bit. plain右移12位后可以又能确定key的16-47位。
…
一直到循环直到确定所有的明文。一共右移4次12位。
[END]